
音声認識系の情報はどれが最適解なのか検討もつかないばかりか、考えてみると、手順みたいなものもなにをやっていいかよくわからない。自分が一番近道だと感じたのはpythonで音声認識を行うこと。とりあえずトレースできる情報はあるので例にならう。
pythonで音声認識をやるには?
pythonで音声認識をやるにはとりあえず必要なソフトとライブラリをインストールすることからはじめなければならない。
- Anacondaのインストール → インストール済み
- SpeechRecognitionのインストール → これはソフトじゃなくてpythonのライブラリ
- pyaudioのインストール → これもライブラリ
- とりあえず.wavファイルの準備 → OBSStudioで適当に録画、Aviutlでwav出力する。というかなんでもいい
- コーディング
まずAnacondaのインストールだけどもう済んでいるので省略。すまん。→ Home – Anaconda
次にSpeechRecognitionのインストール。Anacondaプロンプトを管理者権限で立ち上げて以下のコマンドを入力とのこと。なんか聞かれたけどとりあえずうまくいきました。
conda install -c conda-forge SpeechRecognition
次、pyaudioのインストール。引き続きAnacondaのプロンプトで以下のコマンドをうてばいいらしい。やったけどこれもとりあえずうまくいきました。
pip install pyaudio
本当にインストールされたか確認するには同プロンプトで以下うてばOKかと思います。
pip list
.wavファイルは適当に準備。
コーディング
コーディングというか、サンプルコードは公開されてるんですがね。
英語だと以下のコードになるみたいです。
import speech_recognition
r = speech_recognition.Recognizer()
with speech_recognition.AudioFile("xxx.wav") as source:
audio = r.record(source)
r.recognize_google(audio)
英語はとりあえず使わないので日本語を使いたい。recognize_google()メソッドの第二引数で日本語を指定してやります。実はさきほどのサンプルコードではあえてprint()を書いてませんでしたが、print()を使わないと文字は表示されませんので。
import speech_recognition
r = speech_recognition.Recognizer()
with speech_recognition.AudioFile("oki.wav") as source:
audio = r.record(source)
print(r.recognize_google(audio, language='ja-JP'))
.wavファイルですが、サンプルボイス「生の声」というサイトが非常によいので、このサイトの「沖 直実」さんの声である「oki.wav」ファイルを使用しました。
結果
「こんにちはおきなおみです」のとこが「今日は起きないです」になっているだけであとは完璧です。すごいです。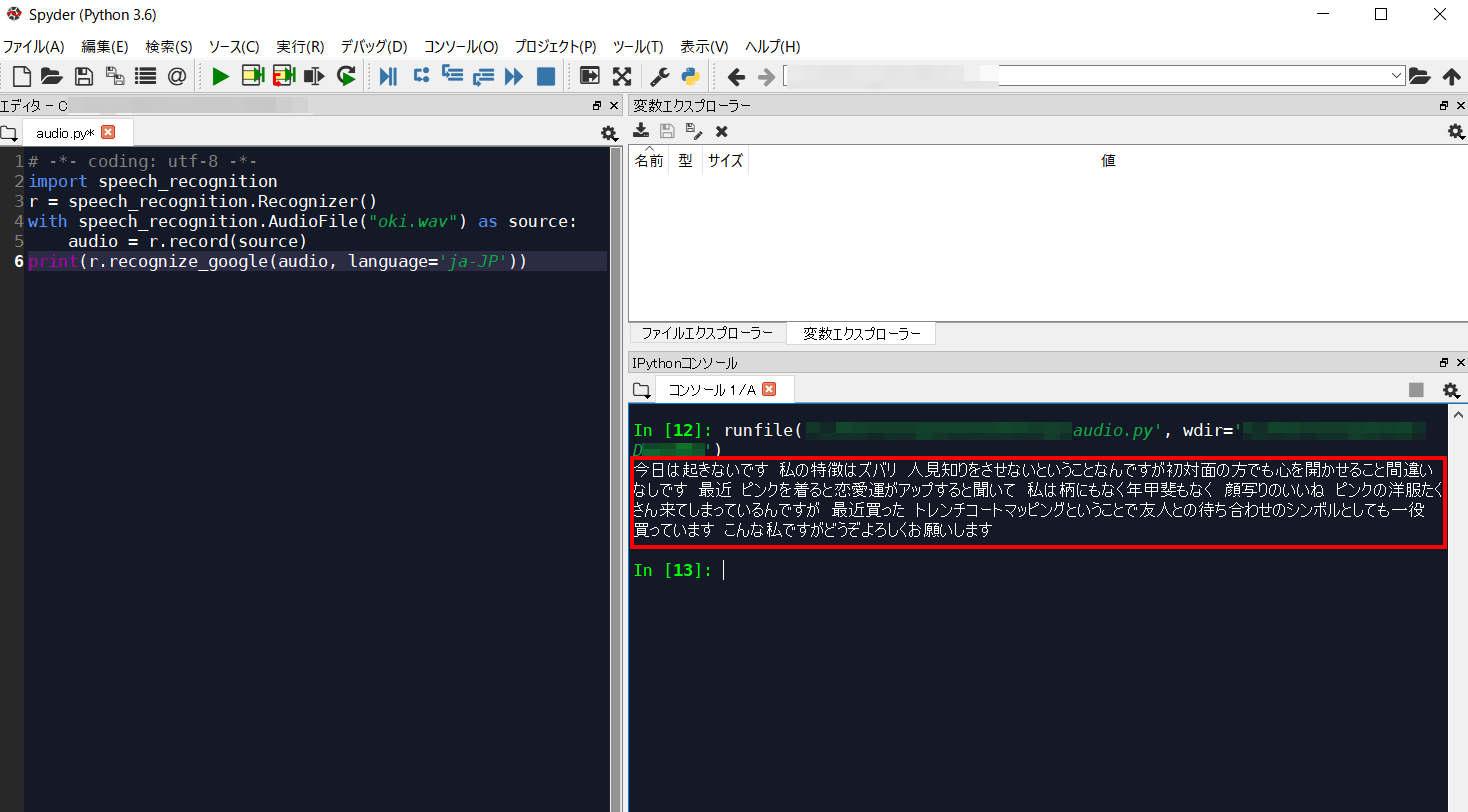
SpeechRecognitionの謎
駆け足でやっているのでSpeechRecognitionってなんなのかがいまいちよくわかってない。Qiitaの情報によると、「いろんな音声認識クラウドサービスを使いやすくしてくれるパッケージです。高機能。」らしい。とりあず情報不足感あり。
pyaudioにかんしては「SpeechRecognitionの動作に必要なようです。」とあり、そうなのかあとうい感じ。と思いきや、SpeechRecognitionの公式に「マイク入力を使う場合にのみ必要」と書かれてあるし!!
コードに目を向けると5行目にr.recognize_google(audio, language=’ja-JP’)と書かれている。regognize_googleということはgoogle系の音声認識エンジンかなにかを使っているようだ。ここでひとつ言えるのは、GoogleクラウドスピーチAPIを使っているわけではないとういうこと。Googleの音声認識サービスは2種類あるっぽい。
SpeechRecognitionの雑感
とりあえず今回わかったのはpythonのSpeechRecognitionというライブラリをつかうと、.wavファイルをテキスト化できるということ。SpeechRecognitionはいろんな音声認識サービスが使えること。いろんな情報あるけど、でたらめよりな情報があるので個人的には公式をみたほうがはやいと感じた。そのうえ必要な情報も集約されている。
こちらどうやらマイクからの音声認識も可能なようである。もう少し情報をおっていきたい。
コメント