
pythonでメルカリの商品名と価格をスクレイピングしてみます。
スクレイピングの準備
pythonでスクレイピングする方法は知る限りでは、seleniumをつかうかbs4とrequestsを使う方法があります。今回は後者をつかいますのでpython構文の冒頭で。
import requests, bs4
メルカリの商品ページから商品名と価格をスクレイピングするコード
検索ワードは入力受付で最初に指定します。スクレイピングをするには、まず該当ウェブページの構造を確認する必要があります。それすらも自動化したいところですが、とりま、その技術はわたしはもちあわせておりません。あるいは単純にコードを組むのがだるいか。
以下がコードです。
import requests, bs4
def mercari(search_word, how_many_page):
pagelist = []
for i in range(1, how_many_page):
page = 'https://www.mercari.com/jp/search/?page={0}&keyword={1}'.format(str(i), search_word)
pagelist.append(page)
for page in pagelist:
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
res = requests.get(page, headers=headers)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text)
elems_name = soup.select('.items-box-name')
elems_price = soup.select('.items-box-price')
for i in range(len(elems_name)):
print(elems_name[i].text)
print(elems_price[i].text)
search_word = input("search_word?: ")
how_many_page = input("how_many_page?: ")
try:
how_many_page = int(how_many_page)
mercari(search_word, how_many_page)
except:
print("you input_key not int")
このコードには商品名と何ページ分取得するかを指定できる柔軟性があります。しかしメルカリにしか使えないコードではあります。
headerは指定しないとなぜかエラーになるので指定します。
このコードは取得したものをプリントするだけなので、csvなどに落とし込みたい場合は別途コードを追加する必要があります。
「soldoutだったら」を実装
とりにくい。だるい。
import requests, bs4, re
def mercari(search_word, how_many_page):
pagelist = []
for i in range(1, how_many_page):
page = 'https://www.mercari.com/jp/search/?page={0}&keyword={1}'.format(str(i), search_word)
pagelist.append(page)
with open('product.csv', 'w', encoding="utf-8") as f:
f.write('name,price,elem' + "\n")
for page in pagelist:
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
res = requests.get(page, headers=headers)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text)
elems_name = soup.select('.items-box-name')
elems_price = soup.select('.items-box-price')
elems_photo = soup.select('.items-box-photo')
for i in range(len(elems_name)):
new_elems_name = elems_name[i].text.replace(",", "")
new_elems_price = elems_price[i].text.replace(",", "").replace("¥ ", "")
new_elems_photo = re.search('figcaption', str(elems_photo[i].__str__))
if new_elems_photo:
f.write(new_elems_name + "," + new_elems_price + "," + new_elems_photo.group(0) + "\n")
else:
f.write(new_elems_name + "," + new_elems_price + "," + "" + "\n")
try:
search_word = input("search_word?: ")
how_many_page = input("how_many_page?: ")
how_many_page = int(how_many_page)
mercari(search_word, how_many_page)
except:
print("how_many_page -> you input key not int")
soldoutだったら figcaption とかいうタグがついている。とるのがくそめんどくさい。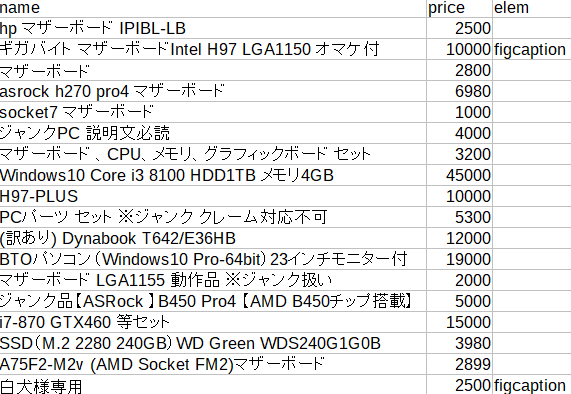
soldoutだったら figcaption という文字がセルに入るようになっているけど、上記を参考に適当に改良すればいいんじゃない?ってかんじ。もうめんどいのでこれ以上はいじらない。
雑感
いろいろやるんだったら、もうちょっと考えないといけないかなという感じ。
コメント
上記コードを試したのですが、requests でアクセスするとなにもデータが出てこないようです。なにか特別な対応が必要でしょうか?
出てこないならクラスが変わってんじゃねえの?
この程度のコードで質問するってことはブラウザの検証もわからないのかな?
chatgptにきけ。コードとエラー貼り付けたら回答でるから