
簡単にWebスクレイピングすることができるChromeの拡張機能「Scraper」を紹介します。
スクレイピングとはなにか?
スクレイピングとはインターネットにある情報を収集することをいいます。次に疑問がわいてくることとしてWEBスクレイピングしたデータをなににつかうの?という疑問です。一般的な用途だと次のようなことが考えられるそうです。
一般的にはHTMLフォーマットからデータベースやスプレッドシートに格納・分析可能な構造化データへの変換に、より焦点が当てられている。また、コンピュータソフトウェアを利用して人間のブラウジングをシミュレートするウェブオートメーションとも関係が深い。ウェブスクレイピングの用途は、オンラインでの価格比較、気象データ監視、ウェブサイトの変更検出、研究、ウェブマッシュアップやウェブデータの統合等である。
わたしは昔pythonを少しかじったことがありますが、beautifulsoupというライブラリをつかうことによって、pythonでWebスクレイピングを少しやったことがあります。そのほかにはseleniumというWebテストツールをつかうことでもスクレイピングができました。しかし最近だとスクレイピングツールがたくさん登場しているようで、ちょっとみただけでも30種類くらいありすごいことになっていました。今回はその中でも使用が簡単そうなChromeの拡張機能として提供されているScraperを使ってみましたので簡単な使い方を紹介していきます。
Scraper拡張機能をインストールする
Scraperの拡張機能インストールで困ることはとくにありません。以下のリンクにいって拡張機能をインストールするだけです。
Scraperの使用方法
ScraperでWebページのコンテンツを取得する
ScraperはJQueryかXPathを選択できる状態になっていて、自分でセレクターや要素を指定することによって目的のデータを取り出せるようになっているようです。デフォルトではJQeuryのa要素になっているようです。ためしに自分のサイトのデータを取得してみました。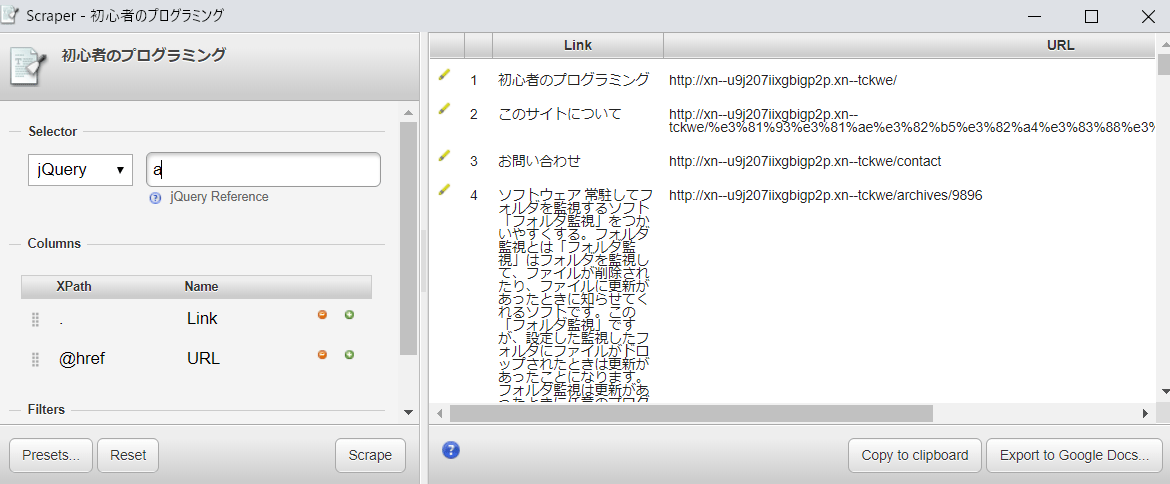
a要素を取得すると、文字列とリンクのURLが自動的に取得されるようですね。
セレクターを指定してみる
自分のブログの記事タイトルのセレクターは.entry-titleなので、このセレクターを指定して、もう一度データを取得してみました。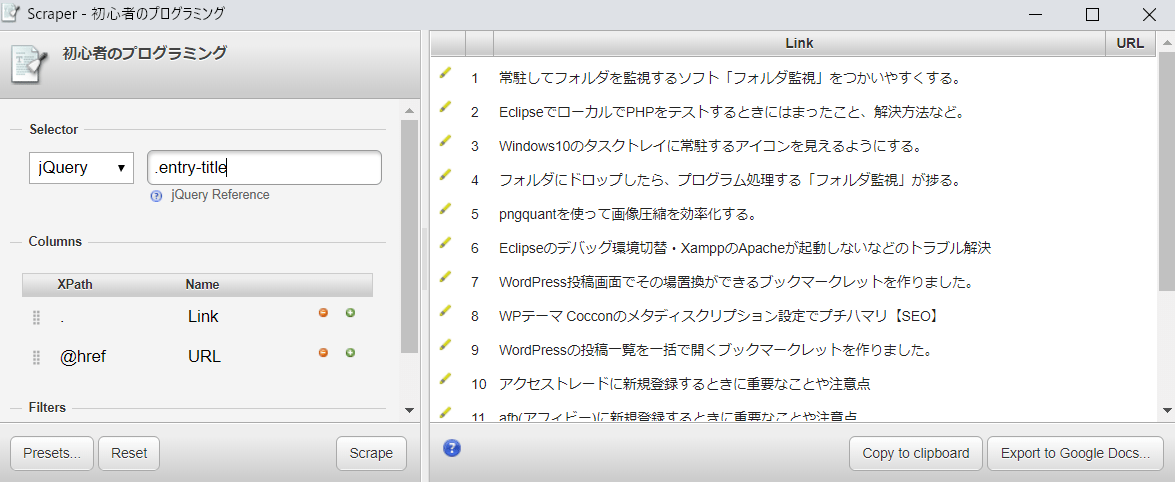
うまくとれていますね。
データをグーグルスプレッドシートに出力する
スクレイピングしたデータはグーグルスプレッドシードに出力できるようです。これを行うには、Scraperの右下のほうにあるExport Google Docsとかかれているところをクリックすると、スプレッドシートに出力することができます。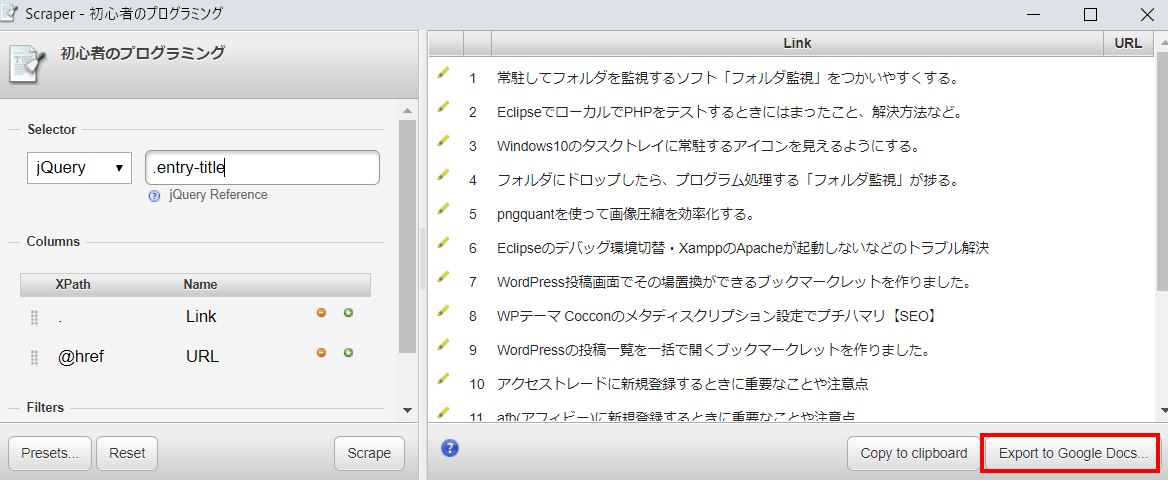
はじめてスプレッドシートに出力するときはグーグルアカウントを選択する画面がでてきますので、それを選択します。
とりあえずうまく出力することができました。
Scraperのまとめ
Scraperを使うと簡単にスクレイピングすることができることがわかりました。しかし、こちらの難点としてはhtmlの知識がないと使用が難しいことかもしれません。htmlを学習するなら以下のようなサイトがおすすめです。
- Progate → プログラミング学習サービス、一部無料
- DotInstall → プログラミング学習サービス、一部無料
- HTMLクイックリファレンス → リファレンスサイト老舗
Scraperの他にもWebスクレイピングツールは数十種類ありますし、これからももっと増えていくんじゃないでしょうか?Scraperのスクレイピング機能はおそらく、スクレイピングのなかでも機能が限定的なので、物足りないと思った方は他のツールをしらべてみるとよいのではないでしょうか。
この記事の情報は以上になります。
コメント