seleniumでうまくスクレイピングできないときはxpathを使用する
selenium以外のやり方を知っている人は、それでスクレイピングすれば良いと思いますが、ログインが必要なサイトなどはseleniumじゃないと厳しい時があります。どうもpython界隈はそんな感じがしています。seleniumは優秀ですが要素がとりにくいときがあります。何度やってもうまくとれないので諦めるほどです。そこでseleniumのfind_element_xpathを使う方法があります。
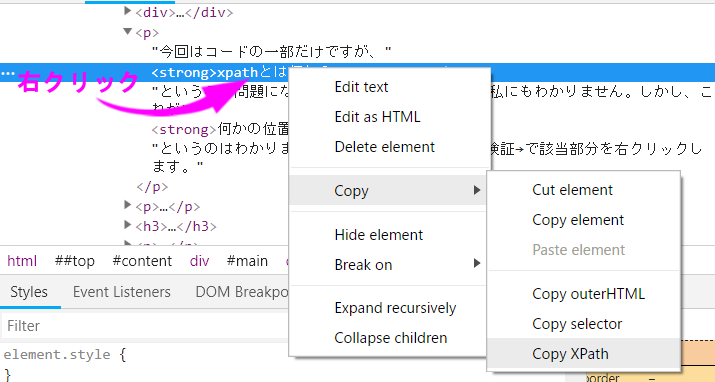
xpathを調べるにはブラウザの要素の検証を使います。
画像のhtmlコードの部分を右クリックするとメニューが表示されますので「Copy」⇒「Copy xpath」をクリックします。するとxpathがコピーされますので、これで要素のxpathを知ることができます。
Pythonでxpathを取得するコード
btn = browser.find_element_by_xpath()
今回はコードの一部だけですが、xpathとは何か?というのが問題になってくると思います。これは私にもわかりません。しかし、これが何かの位置を表しているというのはわかります。xpathを探すには要素の検証→で該当部分を右クリックします。
xpathを見るに、おそらくxpathには規則性があります。ですので、たとえとれなさそうな要素でも、なんとかとることができるでしょう。
役に立つselniumのリファレンス
ありがたいことに日本人がseleniumのリファレンスサイトを作っておられます。ページ下部にリンクを貼っておきます。このサイトはjavaとpythonでのseleniumの使い方を掲載しています。この記事の話はpythonで使うseleniumです。混同しないようにお願いします。
スクレイピングはデータ集めが主目的かもしれませんが、seleniumはウェブ操作を助けます。 インターネットで調べるともともとの目的はウェブテストを自動化するために用いられるツールだったようです。
Seleniumクイックリファレンス

コメント