
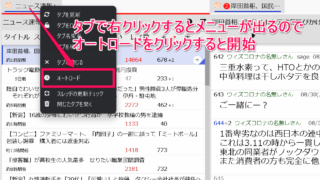
5ちゃんねる対応ビューア 「Siki」のオートロードとオートスクロールの使い方
前回の記事は5ちゃんねる対応ビューア「Siki」を導入~NGワード設定までを書きました。こちらは導入とNGワードの設定までを行...
5ちゃんねる対応ビューア 「Siki」を導入~NGワード設定まで
5ちゃんねる対応ビューアの「Siki」を導入したので導入方法からNGワードを設定するまでの作業を記事化します。ちなみにこの記事...
IFTTTでXとFacebookは連携できるのか?→無料ではできない[2023年8月]
最近IFTTTでXとFacebookを連携したかったので久しぶりにログインしてアブレットを作っていたら、Proしか作れないよう...

Google Apps Scriptの無効なトリガーをスクリプトで削除する
あら?Google Apps Scriptのトリガーって発動したら消えないの?Google Apps Scriptのトリガーは...
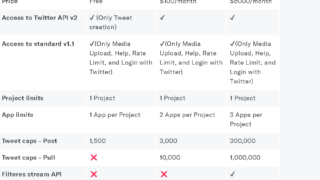
X(旧ツイッター)のAPIって今どうなっているの?[2023年8月]
この記事は2023年8月に書いています。少し前に、ツイッターAPIが廃止される?という噂があったのですが、私はこのときにあまり...

JavaScriptで文字列用に用意した変数の先頭に「undefined」が入ってしまってハマった。
JavaScriptでテキスト用に用意した変数(正確に言えば文字列を代入する予定の変数)に文字列を代入すると先頭になぜか「un...

Google Apps ScriptのUrlFetchApp.fetch()で「Exception: Attribute provided with no value: url」エラー
おっかしいなー。UrlFetchApp.fetch()の引数にちゃんとURLを指定しているんだけどなあー。Google App...
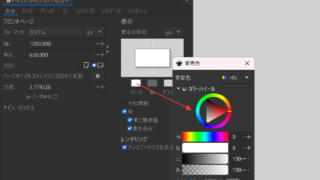
Inkscapeでページの背景色を透明から白色に変更する方法
おっかしいなーー ページの背景色ってドキュメントのプロパティで設定できるはずなんだけどなーInkscapeでページの背景色を透...

Python × Beautiful Soupで画像リンクをスクレイピングしてメディアとして保存する
Pythonを使って画像や動画のリンクをスクレイピングしてそれをメディアとして保存したい。Beautiful Soupの準備B...
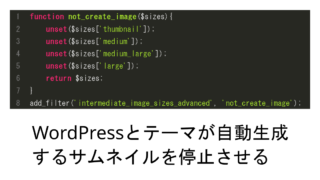
WordPressで自動生成されるサムネイルとテーマで自動生成されるサムネイルを生成しないようにする
WordPressでサムネイルを自動生成させたくないと思った経緯私の場合はロリポップのアップロード可能なファイル数の上限に達し...
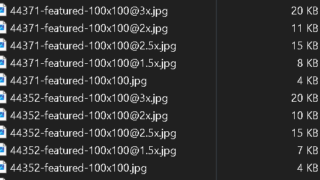
WordPress Popular Postsの画像キャッシュを生成しないようにする
WordPress Popular Postsの画像を生成されないようしたいと思った経緯ちょっと前にロリポップのアップロード可...
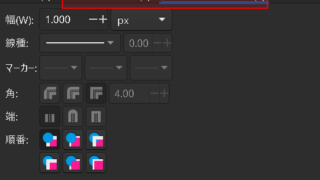
Inkscapeで縁取り文字を作る方法(はストロークを設定すればいいだけ)
あれ?Inkscapeで縁取り文字を作るのってどうやるんだっけ?Inkscapeで縁取り文字を作ろうとしたらそういや作り方知ら...

WordPressで「ファイルのアップロードに失敗しました。アップロードしたファイルをxxxに移動できませんでした」となる原因
WordPressでブログを運営しているのですがある日突然「ファイルのアップロードに失敗しました。アップロードしたファイルをx...

ImageMagickのコマンドを使ってJPEG画像を一括で圧縮する方法
ImageMagickを使おうと思った経緯PNG画像の圧縮はpngquantを使っていたのですが、JPEGの画像は圧縮できない...