
networkxの前にmatplotlib。
必要となる知識
- 準備: pip install matplotlib | anacondaには最初からついてたきもする
- なにができるか: データの可視化。グラフ化
- pythonの基礎文法がわかればたぶんいける。しらんけど。
matplotlibのサンプルコード
基本的には 既存情報 のトレースです。
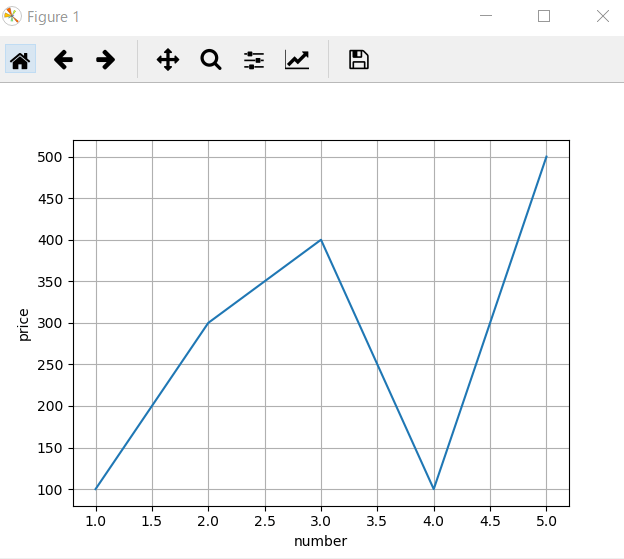
折れ線グラフ
plotを使う。なぜか数字以外を使うとエラーになる。(たぶんやり方はある)
import matplotlib.pyplot as plt
price = [100, 300, 400, 100, 500]
number = [1,2,3,4,5]
plt.plot(number, price)
plt.title = 'fruits_price'
plt.xlabel("number")
plt.ylabel("price")
plt.grid(True)
plt.show()
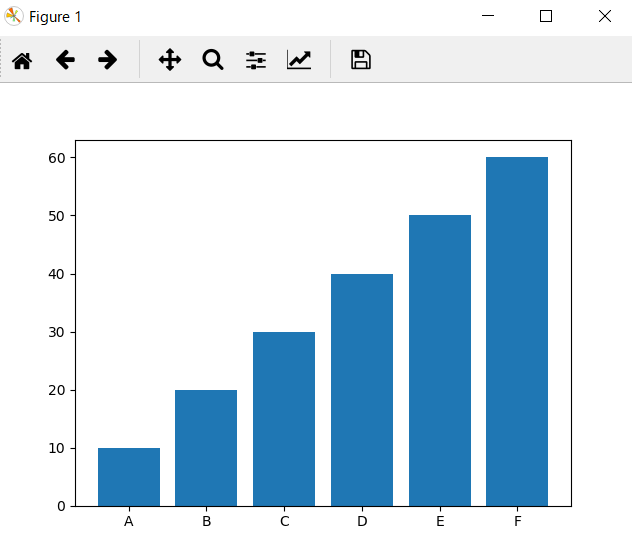
棒グラフ
barを使う。
import matplotlib.pyplot as plt labels = ["A", "B", "C", "D", "E", "F"] y = [10, 20, 30, 40, 50, 60] x = range(0, len(y)) plt.bar(x, y, tick_label = labels) plt.show()
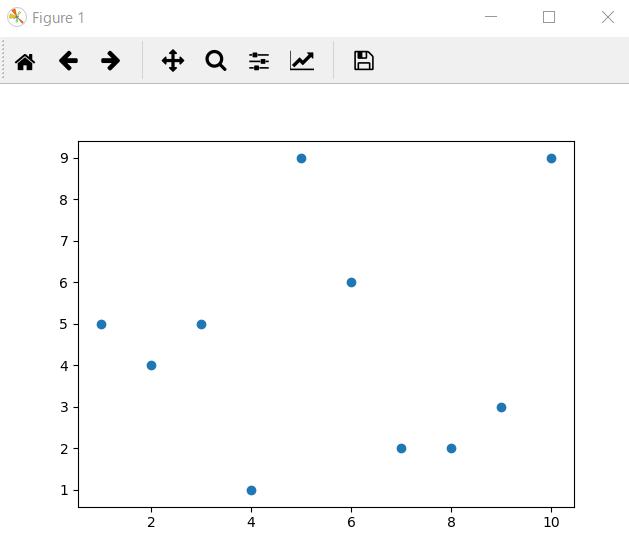
散布図
scatterを使う。書くのがめんどくさい。numpy を使えば簡単にかけるのかしら?とりあえず numpy はおいとくけど。
import matplotlib.pyplot as plt
import random
x = [1,2,3,4,5,6,7,8,9,10]
y = []
for i in range(0, 10):
y.append(random.randint(1, 10))
plt.scatter(x, y)
plt.show()
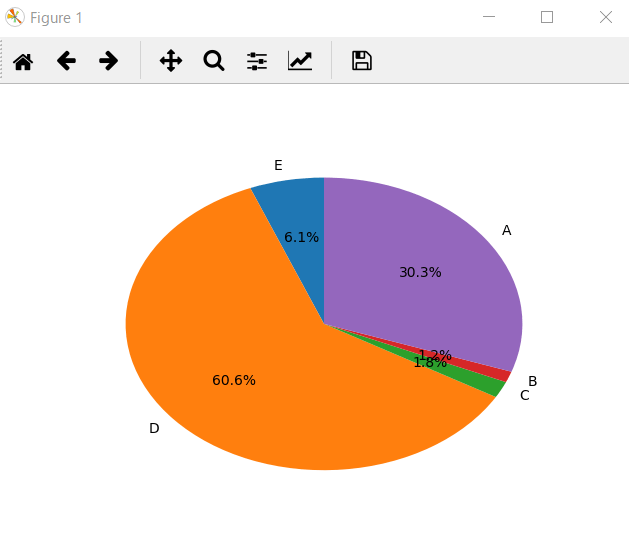
円グラフ
pieを使う。labelは半時計回りに書けばいいらしい。
import matplotlib.pyplot as plt labels = ["E", "D", "C", "B", "A"] y = [100, 1000, 30, 20, 500] plt.pie(y, labels = labels, autopct = '%1.1f%%',startangle = 90) plt.show()
matplotlibを応用してみる
ひとまずわたしのような にわか がグラフを使うのだったら上記の折れ線グラフとか円グラフで事たりるかなと。エクセルつかえばええやろが。となるかもしれないけど、そこは python でやりたい。
準備するもの
適当なテキストファイル。このブログ記事をテキストファイルにしてみる。(sample.txtという名前で保存しました)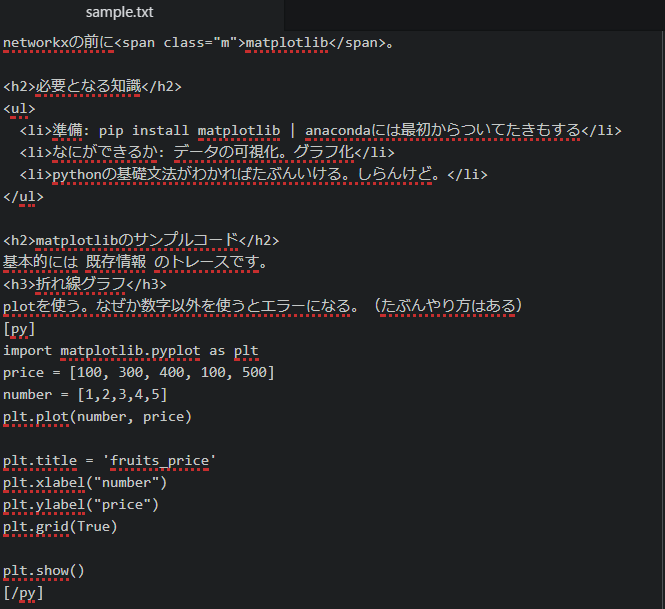
matplotlibでkeyword出現率をしらべる
import matplotlib.pyplot as plt
import re
f = open('sample.txt', 'r', encoding='utf-8')
f = f.read()
_matplotlib = re.findall('matplotlib', f)
_plt = re.findall('plt', f)
_show = re.findall('show', f)
labels = ["show", "plt", "matplotlib"]
y = [len(_show), len(_plt), len(_matplotlib)]
plt.pie(y, labels = labels, autopct = '%1.1f%%',startangle = 90)
plt.show()
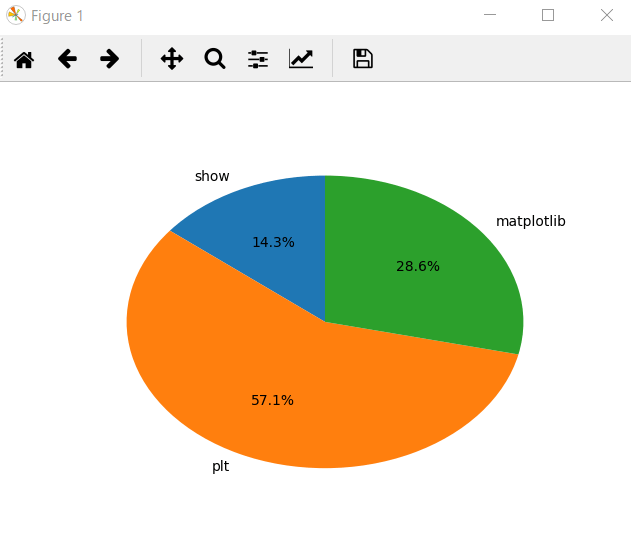
read()メソッドを使うと、ファイルの内容を全部読みこむことができる。そのうえで正規表現をつかう。re.findall()はマッチしたもの全てをリストにして返す。
まとめ・雑感
いつもノンプログラマーっぽいコードになってしまうが、様々なファイルや正規表現に対応したい場合、コードを編集する必要があると思う。
今回はファイル内のキーワード出現率だったが、名前と住所のデータベースから「ここに住んでいる人」は何%とかそういうのも可視化してみたい。
コメント