膨大な物量のpandasモジュール
pandasはデータ分析のための機能が数多くあります。その量は把握しきれないほどです。またほかのモジュールとの連載機能もあり状況がつかみづらい印象になっています(ただの言い訳)
今回はよく使いそうなものを自分で試してみたのでコードをのせたいと思います。コメント行が多くみづらいかもしれません。
import pandas as pd
from matplotlib import pyplot
df = pd.read_csv("output.csv", encoding="shift_jis")
#df = df.dropna()#nullを含む行をカット
df = df.drop(['Unnamed: 0'], axis = 1) #axis = 1は、列、axis = 0は行を指定する
df = df.drop(['URL'], axis = 1)
#データのソート
df = df.sort_values(by=['liked'], ascending=False)
#カラム名の置換
df = df.rename(columns={'liked': 'いいね'})
#スライス
#print(df[5:10])#DataFrame -- こちらは行(rowを指定する)
#カラムをprint
#print(df['いいね'])#Series
#ラベル行をプリント
#print(df.loc[1])#Series -- df.loc[label] →labelとは一番左の項目のこと
#行列の逆転
#df = df.T
#統計情報の表示
print(df.describe())
#図の表示
print(df.hist(['price']))#ヒストグラム
print(df.plot(kind='scatter', x='price', y='いいね'))#散布図
df.head()#上の行をいくつか選んで簡易表示
結果的にはこんな感じになります(画像はspyderのコンソールです。)
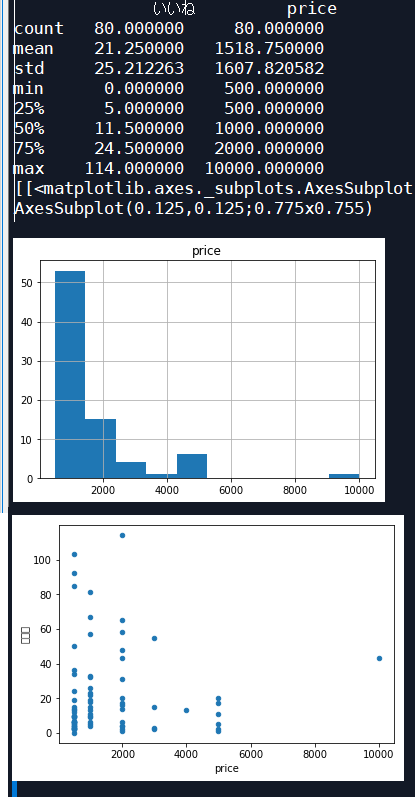
ココナラブルーオーシャンスキル発掘のpandas版です。知らない人からするとココナラって何?ブルーオーシャンって何?pandasって何?となりそうです。むやみに記事を書いているのでそこは置いておきます。
pandasにはDataframeとSeriseという概念があるようです。
pandasには本当に膨大な機能があるので、これは体系的にまとめられたデータサイエンスの技術本とかがないと太刀打ちできないと思います。jupyternotebook使わなくてもspyderのコンソールでよくない?という雑感も・・・
ソートをしたり図を表示したりというのはpandasモジュールを使わなくもできるんだよなあ・・・など思いましたが、pandasはすごい可能性を秘めているのではないかと思いました。アイデアは浮かびませんが、
スクレイピングしたデータの中からスクレイピングしたりすることができればすごいことができそうな予感がします。またpandasは息をするように使いこなすことができれば、非常に強力なデータ分析ツールになりそうです。
pandasモジュールのリファレンスと参考URL
pandas 入門 – pandasによるデータ処理の基礎
http://www.yunabe.jp/docs/pandas_basics.html
Python pandas プロット機能を使いこなす
http://sinhrks.hatenablog.com/entry/2015/11/15/222543
pandas 0.21.0 documentation
https://pandas.pydata.org/pandas-docs/stable/index.html#

コメント