今回はあるサイトを参考に、実際にpythonを使ってhtmlファイルを修正してみたいと思います。まえがきとしてわたしは素人です。コードがかなりぐちゃぐちゃになっています。参考程度にしていただける幸いです。
pythonの正規表現を駆使してhtmlファイル修正案件をこなす
参考URLはこちらです
【業務効率が変わる!】こんな時に役に立つ「正規表現」の使い所 | WebNAUT
正規表現を使って編集するhtmlファイル
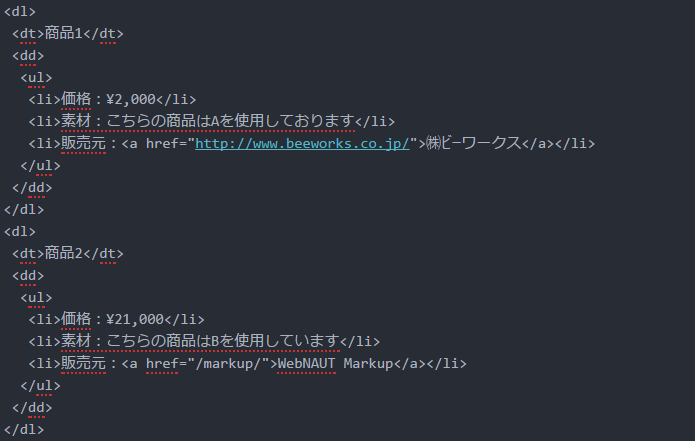
htmlファイルの構造は左のようになっています。htmlをきれいに表示できないので画像にしています。ですが、これは上のリンクページのhtmlファイルと同じです。
pythonを使ってhtmlを修正するプログラムコード
今回はpythonを使ってどのようなプロセスで修正できるのか案をしめします。かなり煩雑なコードです。
import re
from pprint import pprint
file = 'おすきなファイル'
#with open(file, 'w', encoding='utf-8') as f:
with open(file, encoding='utf-8') as f:
content = f.read()
price = re.compile(r'¥(\d{1,3}(,\d{3})*)\b')
content_regex = re.compile(r'¥(\d{1,3}(,\d{3})*)\b')
line_swap = re.compile(r'(<li>素材:[\s\S]*?</li>)([\s\S]*?)(<li>販売元:[\s\S]*?</li>)')
exps = re.compile(r'しております|してます')
#候補を見つける
mo_list = []
mo = content_regex.findall(content)
mo2 = line_swap.findall(content)
mo3 = exps.findall(content)
mo_list.append(mo); mo_list.append(mo2); mo_list.append(mo3)
pprint(mo_list)
#実際に置換する
content = content_regex.sub(r'\1円',content)
content = line_swap.sub(r'\3\2\1', content)
content = exps.sub(r'しています', content)
with open('htmlswap.txt', 'w', encoding='utf-8') as f:
f.write(content)
プログラムコードの解説
- re.compile()のところはソースが崩れていますが、重要なのは、修正されたファイルを作るまでのプロセスです。
- 修正したいファイルをopen()を使って開く
- f.read()でcontentを読み込む。
- 検索するならre.compile(r”)で正規表現をつくる。
- 正規表現オブジェクトをfindallをつかってマッチするものを見つける。→ findall(content)
- 置換をするならsub()メソッドを使う
- 修正後のファイルを作成するなら’w’(書き込みモードで開く)
- f.writeで書き込む withはブロック終了後に自動的にfile.close()
修正後のhtmlファイル
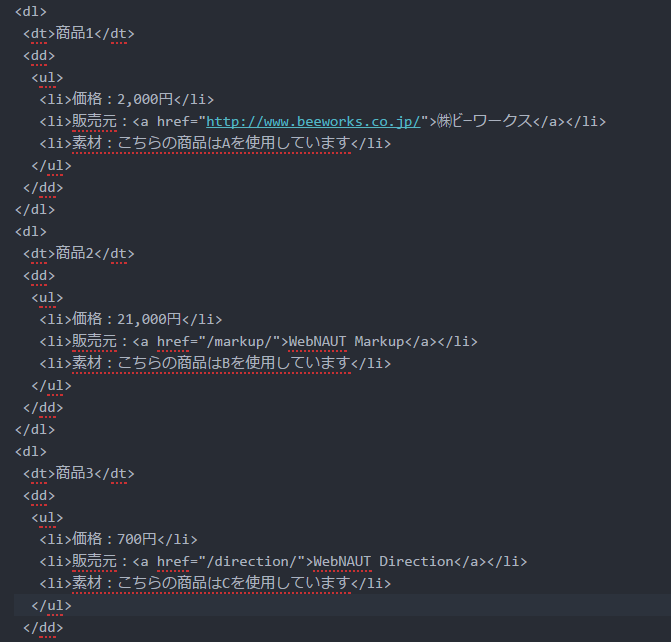 価格の表示がかわり、htmlの「li」要素の表示順序がかわり、また、敬語も統一されました。
価格の表示がかわり、htmlの「li」要素の表示順序がかわり、また、敬語も統一されました。
できることはできましたが、正規表現を作るまでが大変です。これも時間との相談になるでしょうか?pythonの綺麗な正規表現を知っている人がいたら教えてほしいです。それでは。
Pythonの正規表現がある程度わかるようになるリンク
参考にしてください

コメント