
ココナラはスキルを販売できるプラットフォームですがココナラをスクレイピングすることで販売者がどのようなスキルを販売しているか調査することができます。普通にページを閲覧してもよいのでしょうがプログラムで自動的にデータを取得して加工することにやってより情報を見やすくできる場合がありあmす。
利用するモジュール
- selenium
- pandas
- time
今回のスクレピングではSeleniumを使用します。
pandas は、Pythonプログラミング言語でデータ操作と解析を行うための強力なライブラリです。pandas ライブラリは、効率的で柔軟なデータ構造を提供し、データを整理、変換、分析するための多くのツールと機能を提供します。特に、表形式のデータや時系列データの処理に適しています。
ココナラを解析するPythonコード
# ココナラを解析する。 - coconara.py
from selenium import webdriver
import pandas
import time
browser = webdriver.PhantomJS()
browser.get("https://coconala.com/categories/8")
df = pandas.read_csv('trend.csv', index_col=0)
page = 1
while True: # 最後のページを取得するまで続行
if len(browser.find_elements_by_css_selector("a.next")) > 0:
print("######################page: {} ########################".format(page))
print("Starting to get posts...")
time.sleep(5)
posts = browser.find_elements_by_css_selector(".listContentBox") # ページ内のタイトル複数
print(len(posts))
for post in posts:
try:
title = post.find_element_by_css_selector("a.js-service-view-tracker").text
print(title)
detail = post.find_element_by_css_selector("h3").text
print(detail)
price = post.find_element_by_css_selector("strong.red").text
print(price)
liked = post.find_element_by_css_selector("span.overlay").text
print(liked)
url = post.find_element_by_css_selector("a.js-service-view-tracker").get_attribute("href")
se = pandas.Series([title, detail, price, liked, url], ['title', 'detail', 'price', 'liked', 'url'])
df = df.append(se, ignore_index=True)
except:
print("Error: Advertisement appeared. Skipping...")
page += 1
btn = browser.find_element_by_css_selector("a.next").get_attribute("href")
print("next url:{}".format(btn))
browser.get(btn)
print("Moving to next page......")
else:
print("no pager exist anymore")
break
print("Finished Scraping. Writing CSV.......")
df.to_csv("output.csv")
print("DONE")コードの解説
このコードは、coconala.com というウェブサイトから投稿情報をスクレイピングして取得し、pandas ライブラリを使ってデータを整理し、最終的に output.csv という名前のCSVファイルに出力するプログラムです。今回の解説では主にpandasを使っている部分を解説します。Seleniumに関してはセレクターを指定して要素を取得しているだけなので特に解説することはありません。
pandas.Series()
pandas.Seriesは、Pandasのデータ構造で、ラベル付きの1次元データを表します。この行では、投稿のタイトル、詳細、価格、いいね数、URLの情報を元に、新しいSeries(se)を作成しています。pandas.Seriesの第1引数にはデータのリスト、第2引数には対応するラベルのリストが渡されます。
df.append()
dfは既存のDataFrameを表しており、新しい投稿情報を追加するために更新されます。.append()メソッドは、DataFrameに新しい行(Series)を追加するためのPandasのメソッドです。第1引数には追加するSeriesを、第2引数のignore_index=Trueは新しい行のインデックスを自動的に再設定することを意味します。これにより、新しい行がDataFrameの末尾に追加されます。
LibreOfficeで出力したCSVを閲覧
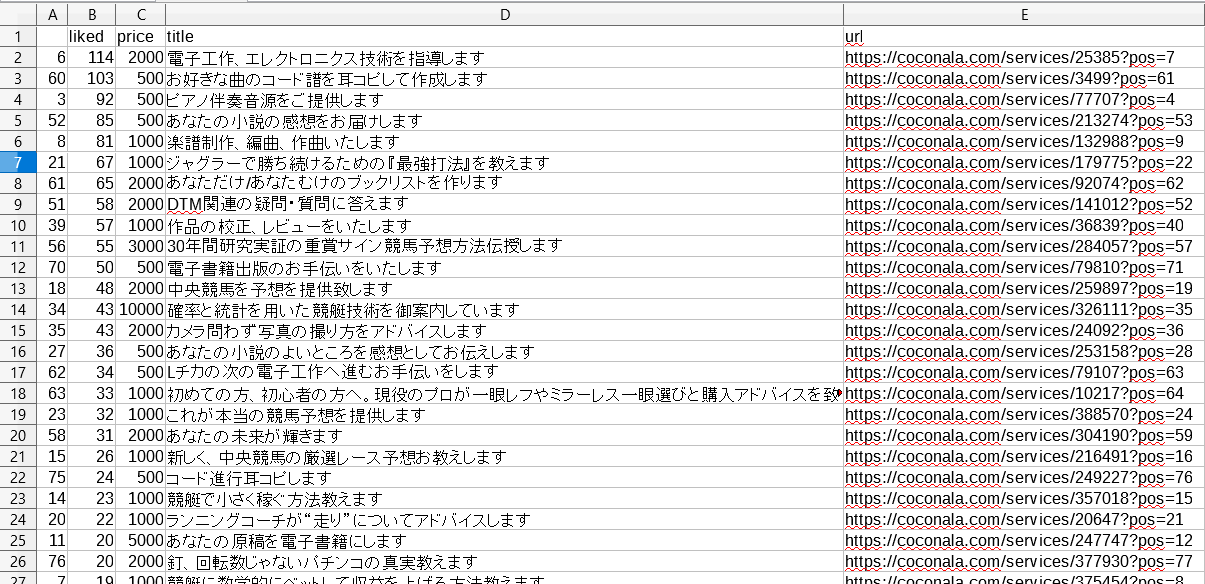
LibreOfficeでいいね数(列=lilkes)をソートするには 「データ」タブをクリックして→昇順か降順に並べ替えるをクリックします。 いいね数を降順にソートした結果、音楽とギャンブルのジャンルがよく売れているようでした。
まとめ
このプログラムはあくまでもデータを取得しているだけです。しかしpandasを介してCSVに出力しているため、表計算ソフト等でデータを(ソートして)閲覧することでココナラで売れているサービスなどを把握することができるでしょう。補足として扱ったデータは単純なものなのでわざわざpandasを使わなくてもPythonのcsvモジュールでも代用できます。
そしてこの記事なんですが2017年に書いているもので現(2023/08リライト)時点ではココナラのページの構造や要素のクラスなどが大幅に変わっているためこのプログラムではおそらくデータを取得できないと思います。しかし基本的なアプローチは同じですので、ココナラのページを調査してプログラムを修正すればデータは取得できます。

コメント