政府のブラック企業PDFデータをエクセルに変えそこから整形する。
データ分析が少し流行っているような気がしますが、データをどう料理するかまでは素人の手がおよぶところではありません。しかしにわかパイソニスタが考えるデータ分析の最良の手段はこれです。
- いかにデータ整形に時間をかけないか。
- データは一目見た瞬間に大量の情報が入るようにする。
まず政府のサイトからブラック企業データをダウンロードします。ダウンロードされたデータはPDFです。上記の「いかにデータ整形に時間をかけないか」という原則に従いますと、これはウェブサービスでエクセルに変換します。するとこのようなデータになります。

非常に綺麗に出力されており、驚くほどです。しかもページ分は「Table」というシートに変換されています。素晴らしいです。問題はこのエクセルデータだと一目みただけで情報は入ってくるだろうか・・・というのはあります。(たとえるならば一口では食べられないという表現でしょうか)
これを上記の「データは一目見た瞬間に大量の情報が入るようにする。」という原則に従いpythonで整形します。
エクセルファイルをPythonで整形する
import openpyxl
from openpyxl.styles import Font
font_obj = Font(size=6)
wb = openpyxl.load_workbook('170510-01.xlsx')
for i in range(1, 60):
sheet = wb.get_sheet_by_name('Table {}'.format(str(i)))
for i in range(1,33):
sheet.row_dimensions[i].height = 15
for row in sheet['E1':'F33']:
for cell in row:
cell.font = font_obj
wb.save('black.xlsx')
このコードはforループを4重ループにしています。これは説明しても理解できないかもしれません。シートは(Table)は60シートあります。また行の幅を変えたいのでrange(1,33)で33行分です。特定のセルだけ文字を小さくしたいので、for row in sheet[”:”]という形にしています。for cell in row:としているのには一応理由はありますがここでは説明は省きます。
こんなことしているようなデータラングラーはいないと思います。こんな最悪のコードを書く以外にきっとなにかいい方法があるはずです。結果はこのようになります。
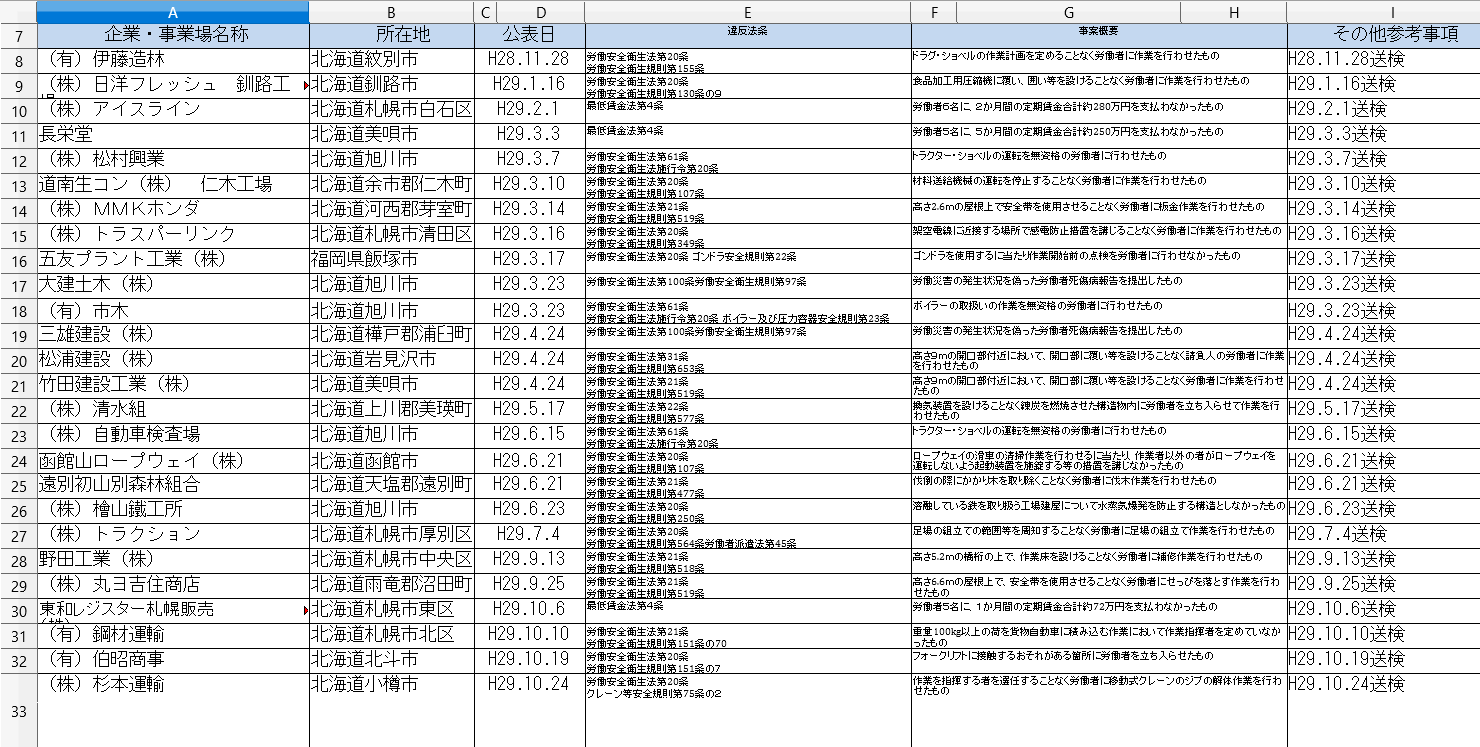
これであれば目だけでなめることができるでしょう。プログラム通り全てのシートに反映されています。しかし問題点はあります。全てのシートで同じセルが同じ項目とは限らないからです。にわかにはここらへんが限界かもしれません。
別にエクセルでもできるんじゃない?
エクセルを開き全てのシートを選択すれば同様のことはできます。しかしこのエクセルファイルは60シート分もあり動作が遅すぎてイライラしてしまうかもしれません。一方pythonを使った場合は5秒ほどで完了します。
ところがコーディングの時間を含めると話は別になります。そのためエクセルのデータを整形することを考えるのであれば、プログラムと手作業で時間がかからないほうを選ぶ必要があります。
ファイルの様子をみてコーディング方法を考えるというプロセスは意外に大きいものがあります。このあたりはまだ研究する余地があります。

コメント