
Network Visualizationって はったり なのかな?
Gephiの使い方① node_csv と edge_csv
データを用意する
Gephiを理解するには小さなデータからはじめるのをすすめる。いきなりだが以下にある情報をトレースするのがよいだろう。
参考 → 「Importing csv data in Gephi」
Gephiにはnodeとedgeという概念がある。nodeは点でedgeは線となる。
node用のcsvデータには「IdカラムとLabelカラム」が必須となる。
edge用のcsvデータには「SourceカラムとTargetカラム」が必須となる。
まず上記サイトを参考に、node用のcsvデータを作る。
次にedge用のcsvデータだ。
これらのcsvデータは最初、一目みただけでは関係がよくからない。だがGephiに読み込むとだいたいわかる。
nodeのcsvデータをgephiに読み込む
まずはnode用のcsvを読み込む。「データ工房」→「ノード」→「スプレッドシートのインポート」を選択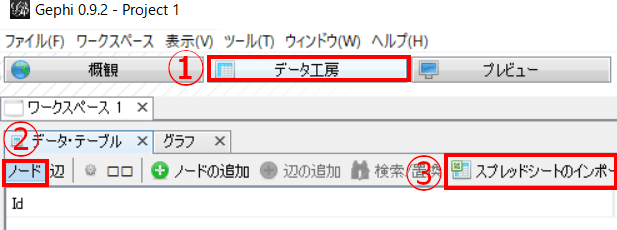
とりあえずすすめる。大事なのは「Append to existing work space」を選ぶことだ。これを選んでおかないと新たにワークスペースが作られてしまう。あと画像は貼り付けてないがノード用なので「node table」をえらぶこと。
「概観」で結果を確認する。この時点ではノード、つまり「点」だけしか表示されていないことがわかるだろう。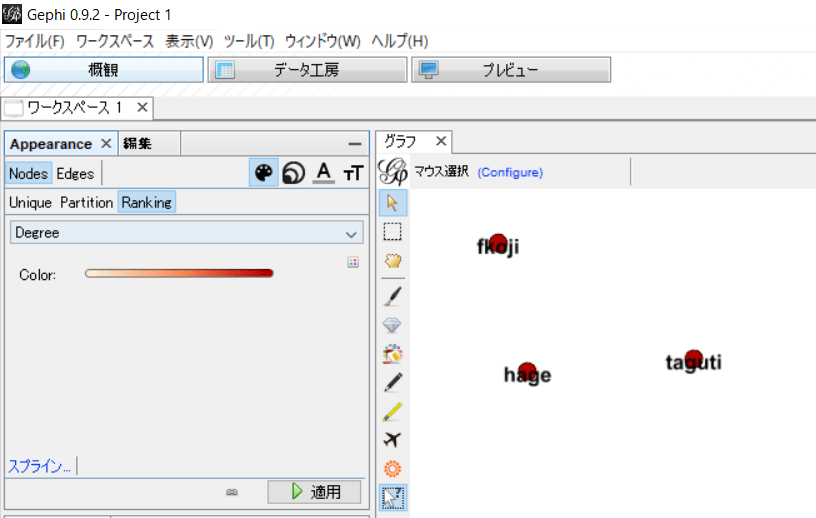
edgeのcsvデータをgephiに読み込む
nodeのときと同じ手順だ。
今回はedgeのcsv。なのでEdge tableを選ぶこと。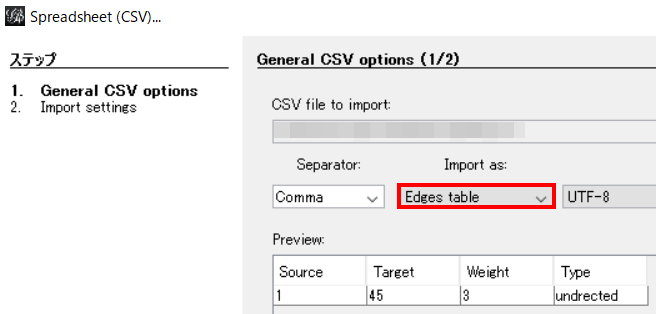
結果はこうなる。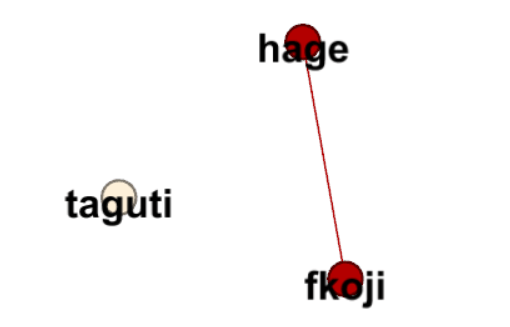
なめてんのか?と思われたかもしれないが、この結果には重要な情報が含まれている。edge用のcsvで「Sourceは1」は「Targetは45」としている。nodecsvに目を向けてみると「id1はfkoji」「id45はhage」としている。これでもうわかっただろう。edgeのsourceとtargetが線で結ばれていることが。ここが重要なのである。
次には「Weight」これは線の太さではない。おそらく「重み」である。だが気にしなくてもいい。次に「Type」今回はTypeの値を”undirected”にしている。この場合はedgeが矢印ではなくなるということだ。”directed”にしていればedgeが矢印になるということ。ちなみにWeight、Typeカラムは省略していい。
ここまで一連の流れを見てきたがこう思っただろう「こざかしい」と。
Gephiの使い方② 隣接リストとしてインポートする
隣接リストでのcsv読み込み
いままでみてきたのは nodeとedgeのcsvで2つのcsvファイルを用意する必要があった。しかし「Adjacency list」、つまりは「隣接リスト」という項目をえらぶことにより、隣接カラムデータに自動でEdgeをつけてくれるようになる。このモードでimportした場合は、csvデータは1つで良い。
また、「カラムヘッダーは記述する必要はない(Id, Label等)」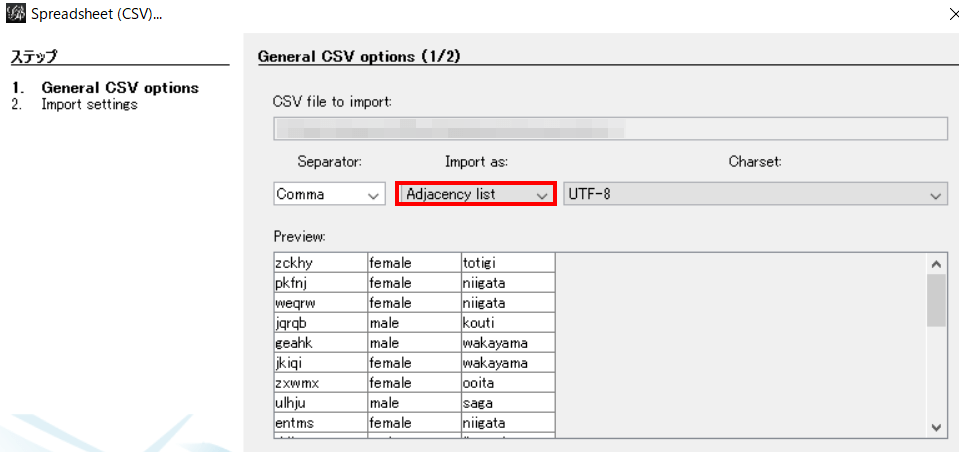
Adajacency list用のデータを用意
例は悪いかもしれないが、「名前、住所、性別」のデータ1000件分を用意しよう。
pythonコードだ。
fragment = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
place = ['hokkaido','aomori','iwate','miyagi','akita','yamagata','fukusima','ibaragi','totigi','gunma','saitama','tiba','toukyo','kanagawa','niigata','toyama','isikawa','fukui','yamanasi','nagano','gifu','sizuoka','aiti','mie','siga','kyoto','oosaka','hyogo','nara','wakayama','tottori','simane','okayama','hirosima','yamaguti','tokusima','kagawa','ehime','kouti','fukuoka','saga','nagasaki','kumamoto','ooita','miyazaki','kagosima','okinawa']
gender = ["male", "female"]
label = ""
with open('pepole.place_gender.csv', 'w') as f:
for i in range(1,1000):
for j in range(0, 5):
label += random.choice(fragment)
f.write(label + "," + random.choice(gender) + "," + random.choice(place) + "\n")
label = ""
概観で結果を確認する
今回は極端な例だが、以下のようになる。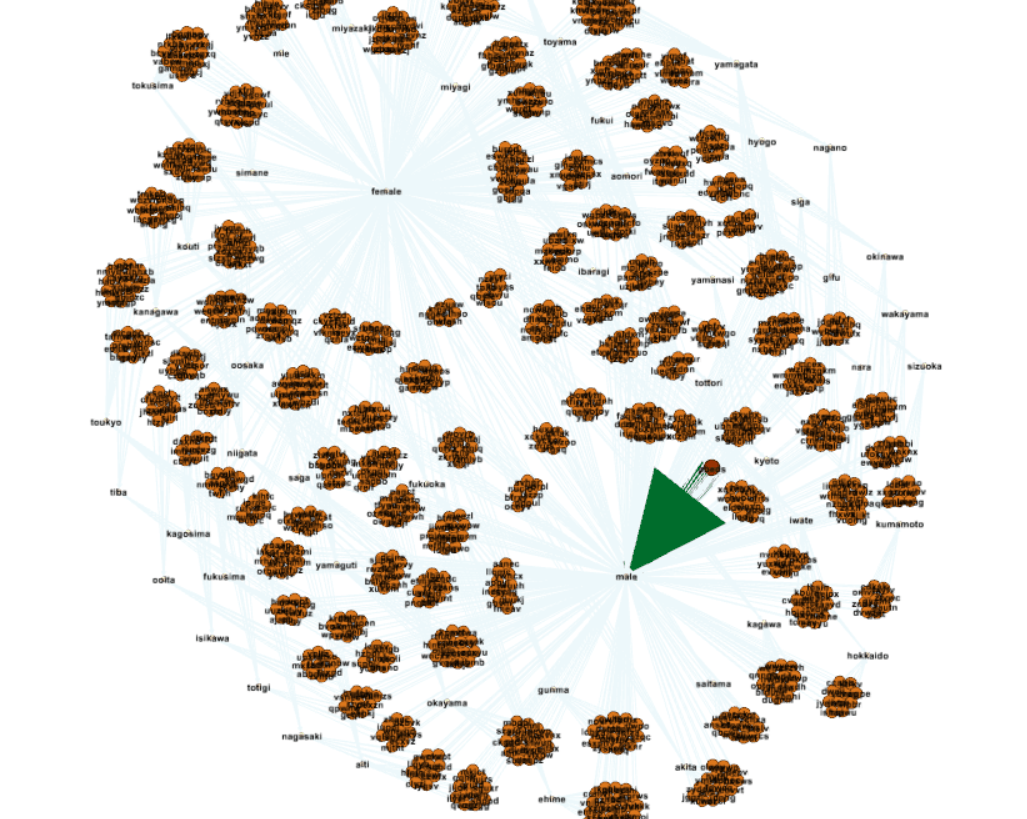
ちなみにノードにカーソルを合わせると、それに対応したデータのみが濃く可視化され回りは薄くなる。
しかしこれができたところで何になるんだ?
雑感 Gephiは必要か?
必要ない。
こういうのがやりたかったわけではない。とりあえずもうちょっと探す方向で。
コメント