
どうも。surface pro4が70000円で売っていて激安だ!と驚きましたが、2世代前の商品だったことに気づいていませんでした。
メルカリ商品データを分析する
こちらの記事で、メルカリの「商品名、価格、売り切れ」のデータをとるプログラムを書きました。
pythonでメルカリの商品名と価格をスクレイピングする。
いろいろ考えるフリをしていましたが、ざっくりまとめるとこのような方針です。
- 既出情報のトレース
- 価格を四捨五入する必要はない。
- とりあえず、コードは汚くてもいいのでfor文で回す
肝ではないですが、価格を「四捨五入する必要がない」ってことに気づくのにわりと時間がかかったきはします。ちなみにpythonで整数を四捨五入する簡単な方法は以下の記事に掲載しています。
python プラス マイナス変換。整数の四捨五入などの小技
データの構造
前回記事にのせた csvの画像 です。うーん・・・眺めていても、頭の中でコードがかけません。手を動かしながらというようになりそうです。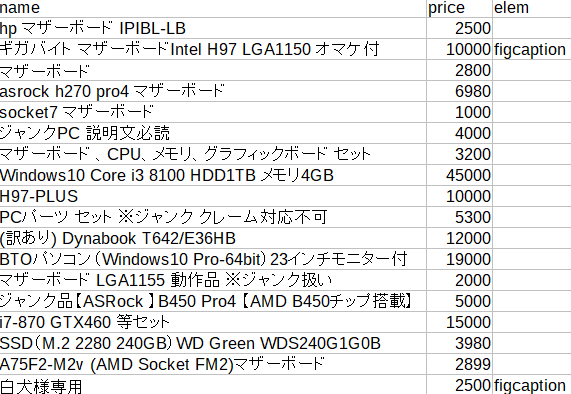
最善策ではないのはないにしろ。2通りあるかと思います。
- pandasモジュール をつかうか
- csvモジュール をつかうか
pandas は便利なのですが、データフレームオブジェクトのせいで癖があります。といいつつ今回はpandasを使います。
〇万円代の商品が売れているか売れてないかを取得する
〇万円代の商品が売れているか売れてないかを知りたかったとします。ぶっちゃけ既出情報の模倣なわけですが、なんというか言葉じゃ説明しにくいです。コード見ればたぶんわかるかなと。
import pandas as pd
def sold_or_nosold(price_list, sold_list, price_size):
for price, sold in zip(price_list, sold_list):
if price_size <= int(price) and price_size + 10000 > int(price) and sold == "figcaption":
yield "sold"
if price_size <= int(price) and price_size + 10000 > int(price) and pd.isnull(sold):
yield "nosold"
df = pd.read_csv('product.csv')
price_list = df['price']
sold_list = df['elem']
# これはコメントです
'''
sol_count = 0
no_sol_count = 0
'''
for s in sold_or_nosold(price_list, sold_list, 10000):
print(s)
# これはコメントです
'''
if s == "sold":
sol_count += 1
elif s == "nosold":
no_sol_count += 1
print("sol_count: " + str(sol_count))
print("no_sol_count: " + str(no_sol_count))
'''
まずメルカリの商品は、売り切れの場合、figcaptionというhtmlタグがつきます。ですので、csvデータの売れている商品にはelem列にfigcaptionという文字があるわけです。(前回そういうコードにしたので)elemという名前は適当につけた名前でそこは気にしないでください。
pandasはどうも肌に合わないのですが知識不足感が強いです。ひとまずpriceカラムとelemカラムのデータを取得し、それをfor文とzipを使って2個同時に回します。
sold_or_nosold()メソッドの第三引数 price_size に例えば 10000 と設定した場合、10000円以上20000万円以下の商品だけを取得できます。加えてfigcaptionの文字があったら「売れてる」を返すわけですね!
次に「売り切れてない」の条件です。こちらが非常にめんどくさいのですが、pandasでcsvを読みこむと空白のセルは NaNという特殊な値になります。(そもそもデータフレームオブジェクトですのでセルという概念はないとは思いますが。)
NaNを比較するにはいろいろなやり方がありますが、pandasの isnull() というメソッドを使うとNaNを比較できるようです。
雑感
センスがない。あと yieldとかはじめてつかったぞ。yieldってジェネレーターっていうらしいね。
コメント